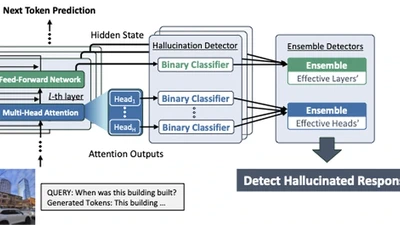
EnsemHalDet: Robust VLM Hallucination Detection via Ensemble of Internal State Detectors
Vision-Language Models (VLMs) excel at multimodal tasks, but they remain vulnerable to hallucinations that are factually incorrect or ungrounded in the input image. Recent work …